News
- Oct. 3, 2024: We release DA-Code, an agent data science code generation benchmark for large language models.
- Sep. 24, 2024: Our paper is accepted by EMNLP 2024.
Data Examples

Have Questions?
Ask us questions at our Github issues
page or contact Yiming Huang, Jianwen Luo, Fangyu Lei for more information.
Data Statistics
We present an overview of DA-Code’s data statistics, showcasing its structure and variety of tasks. DA-Code contains 500 tasks in total, categorized into Data Wrangling (DW), Machine Learning (ML), and Exploratory Data Analysis (EDA).
The ML tasks are comprised of sub-tasks such as Classification, Regression, and Clustering. EDA includes Visualization, Statistical Analysis, Data Insights, and Data Manipulation, while DW encompasses tasks such as Data Loading, Cleaning, and Transformation.
The ML tasks are comprised of sub-tasks such as Classification, Regression, and Clustering. EDA includes Visualization, Statistical Analysis, Data Insights, and Data Manipulation, while DW encompasses tasks such as Data Loading, Cleaning, and Transformation.
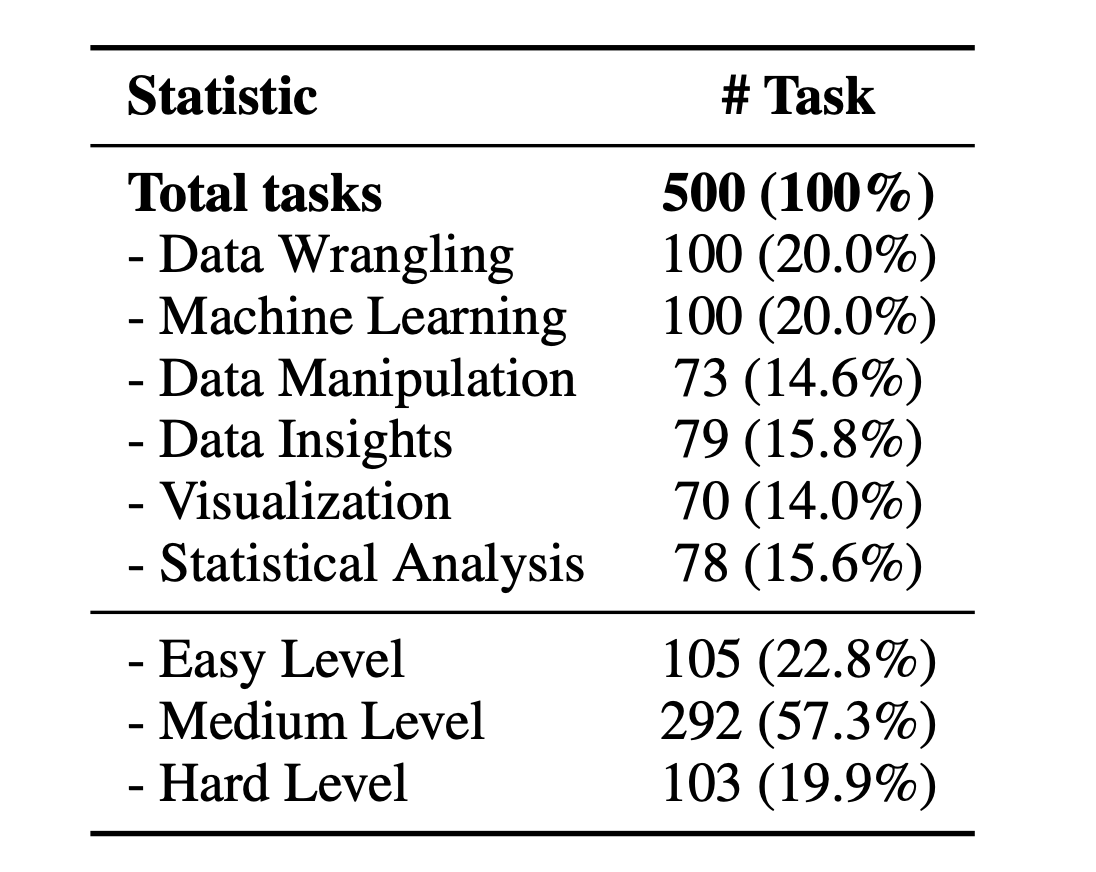
Data Statistics of Examples in DA-Code
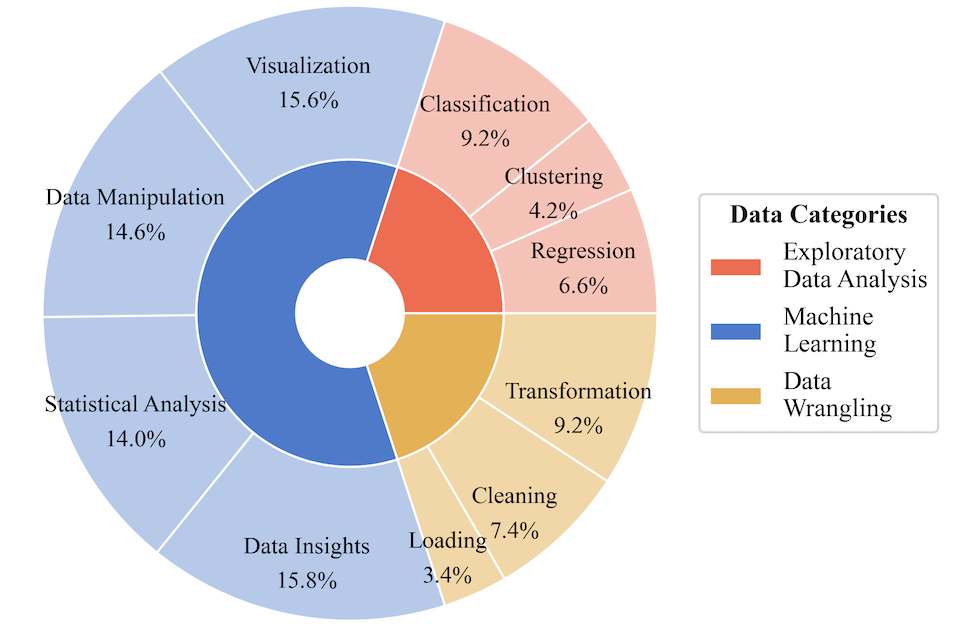
DA-Code Task Types Proportion
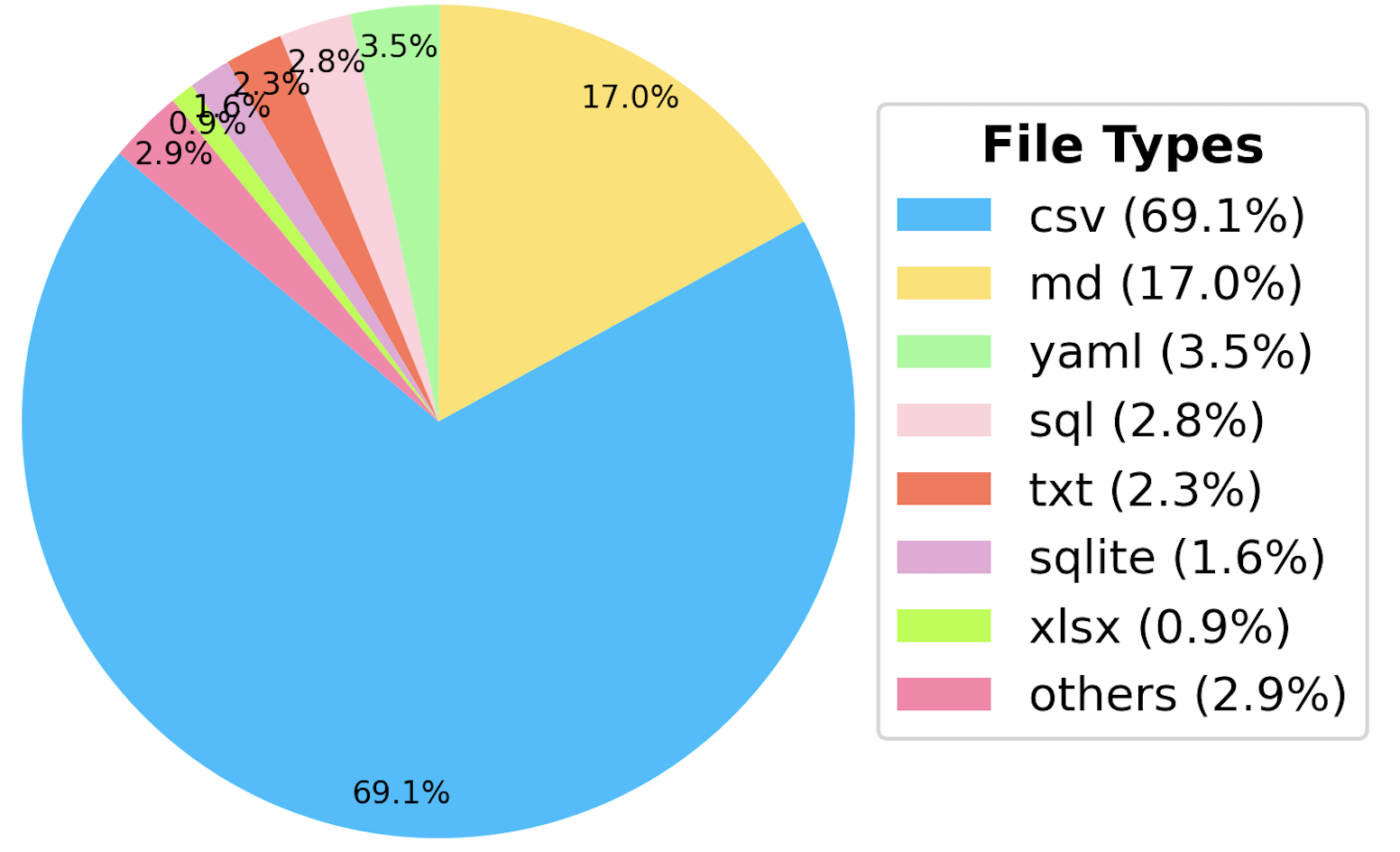
DA-Code File Types Proportion